Adaptive Reward Sharing to Enhance Learning
in the Context of Multiagent Teams
Kyle Tilbury* and David Radke*
* denotes equal contribution
Proceedings: Reinforcement Learning Conference (RLC) 2025
[Click for Paper]
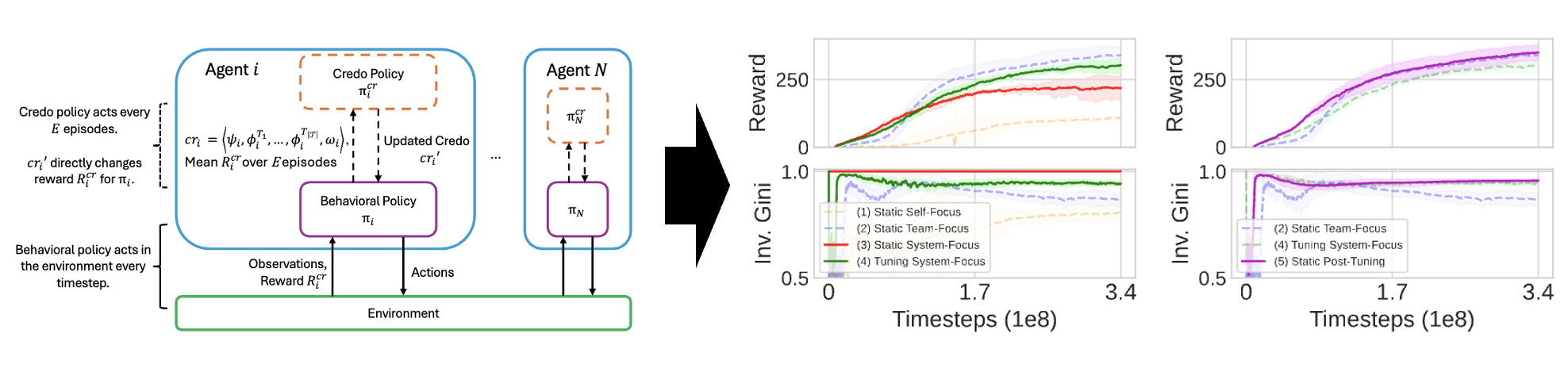
Abstract:
Real-world populations include diverse social structures, such as sub-groups or teams,
that create heterogeneous incentives that complicate coordination. Agents learning to
cooperate in these dynamic environments must be able to adapt their internal incentives
with their surroundings. We address this challenge with a decentralized multiagent
reinforcement learning framework in which each agent has two policies, a low-level
behavioral policy and a high-level reward-sharing policy, to adapt both its behavior
and its reward function within mixed-motive environments with social structure. We
demonstrate the viability of our approach by showing that agents coordinate more effectively through this simultaneous adaptation of heterogeneous reward-sharing configurations. Empirically, our framework enhances population-level outcomes, overcoming
sub-optimal initializations and surpassing non-adaptive fully-cooperative baselines in
two evaluation domains. Furthermore, the heterogeneous reward-sharing parameterizations that our method learns prove highly effective when applied to new agent populations, yet identifying such configurations through exhaustive or heuristic search is
burdensome in this complex search space. By enabling agents to learn and adapt to heterogeneous reward-sharing schemes, our work better captures more diverse dynamics
with social structures and varying incentives.