Dynamic Reward Sharing to Enhance Learning
in the Context of Multiagent Teams
Kyle Tilbury* and David Radke*
* denotes equal contribution
Proceedings: AAMAS 2025 Extended Abstract
[Click for Paper]
Abstract:
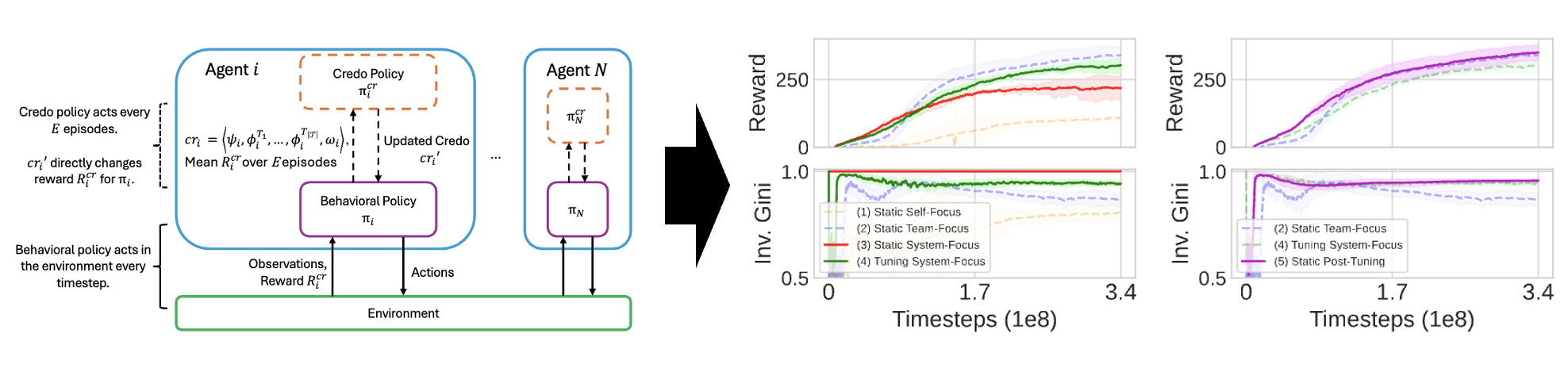
In multiagent environments with individual learning agents, social
structure, defined through shared rewards, has been shown to significantly impact how agents learn. However, defining reward-sharing
parameters within a social structure that best support learning
remains a challenging, domain-dependent problem. We address
this challenge with a decentralized framework inspired by metareinforcement learning where independent reinforcement learning
(RL) agents dynamically learn reward-sharing hyperparameters using a secondary RL policy. Agents’ secondary RL policies shape the
reward function and guide the learning process for their primary
behavioral policies acting within a multiagent RL (MARL) environment. We show that our process enhances individual learning and
population-level outcomes for overall reward and equality compared to agents without this secondary reward function shaping
policy. Furthermore, we show that our framework learns highly
effective heterogeneous reward-sharing parameters.